在了解Lucene之前,我们先看下什么是搜索引擎?
在实际的项目中,我们可能会写了类似这样的SQL。
按标题模糊查询,查询标题与xxxxx有关的新闻:
select * from t_news where title like ‘%xxxxx%’;
按关键字查询 ,如查询与xxxx有关的新闻:
select * from t_news
where title like '%苍老师%' or content like '%苍老师'’;
当数据量变大时,这四个查询都变慢了,我们可能会建立索引,但是有的like语句会使索引失效。
可能有的需求对搜索的结果进项相关度排名的显示,对应的sql是否可以满足需求吗?
例如:
要查询 中国、冠状病毒、复工有关的新闻:
含有三个关键字(相关度最高)的新闻排前面
含两个关键字(相关度次之),排次之
含一个关键字 的,排次次之。
这时利用数据库sql实现还是比较困难的。
数据库适合结构化数据的精确查询,而不适合半结构化、非结构化数据的模糊查询及灵活搜索(特别是数据量大时),无法提供想要的实时性。
这个问题,一个解决思路是:
我们查询时,输入的是冠状病毒,想要得到标题或内容中包含“冠状病毒”的新闻列表。
如果标题、内容列上都有一个这样的索引,里面能快速找到与冠状病毒关键字对应的文章id,再根据文章id就可以快速找到文章了。
倒排索引
上面建立索引就是倒排索引,或者又叫做反向索引。
例如:
标题列索引:


内容类索引:
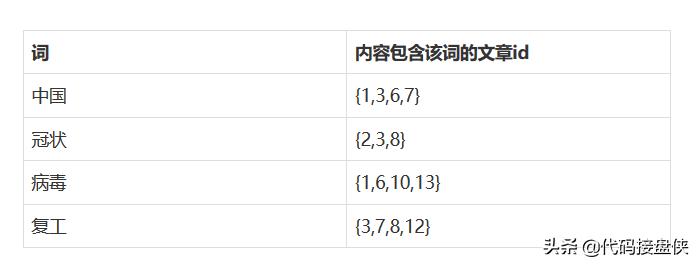
这么多的词,那么需要建立多少个词呢?
反向索引的记录数会不会很大?

通过上面的看,词的总数也不多,那怎么分词,也就是怎么把一句话分成很多常用的词呢?
这时就需要用到了分词器。
分词器
分词器,可以将一段语句分出若干个词。
英文:this is my car 分词后:this,is,my,car
中文:今日头条厉害。今日头条,厉害
常用的中文分词器:
word分词器,Stanford分词器,Ansj分词器,smartcn分词器,FudanNLP分词器,
IKAnalyzer分词等。
有了分词器,还可以获取词在文章的位置,出现的次数。此时可以这样的索引:
词:中国,
内容包含该词的文章id:
{{1,2,{21,32}},{5,3,{18,29,45}}}
1:文章id
2:出现的次数
{21,22}:出现的位置
建立好了这样的反向索引,那怎么索引呢?
步骤1: 对搜索输入的内容进行分词
步骤2: 在反向索引中找出包含中国、复工的文章列表

步骤3: 合并两个列表,排序输出
{1,12,8,5}
输出结果,那怎么排序输入结果呢?把最关注的放到最前面。怎么建立一个相关性评估模型?
这时可以按照词的出现的次数建立模型,当然还有其他的模型来面对更复杂的场景。
统计出现次数,根据次数从高到低排:
中国

排序后:
{{1,5},{5,3},{12,1},{8,1}}
文章id为1,总共出现了5词,文章id为5的出现了3词。。。
其他的复杂的相关性计算模型有:
tf-idf 词频-逆文档率模型
向量空间模型
贝叶斯概率模型,如: BM25
搜索引擎中会提供一种、或多种实现供选择使用,也会提供扩展。
电商网站中的搜索相关性计算会考虑更多,更复杂。
这里引入什么是搜索引擎?
搜索引擎
一套可对大量结构化、半结构化数据、非结构化文本类数据进行实时搜索的专门软件。
最早应用于信息检索领域,经谷歌、百度等公司推出网页搜索而为大众广知。后又被各大电商网站采用来做网站的商品搜索。现广泛应用于各行业、互联网应用。
搜索引擎专门解决大量结构化、半结构化数据、非结构化文本类数据的实时检索问题。这种实时搜索数据库做不了。
使用场景:
信息检索(如电子图书馆、电子档案馆)
网页搜索
内容提供网站的内容搜索(如 新闻、论坛、博客网站)
电子商务网站的商品搜索
如果你负责的系统数据量大,通过数据库检索慢,可以考虑用搜索引擎来专门负责检索。
核心部件:
数据源
分词器
反向索引(倒排索引)
相关性计算模型
工作原理:
从数据源加载数据,分词、建立反向索引
搜索时,对搜索输入进行分词,查找反向索引
计算相关性,排序,输出
开源搜索引擎组件、系统:

Lucene:Apache顶级开源项目,Lucene-core是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的框架,提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Nutch:Apache顶级开源项目,包含网络爬虫和搜索引擎(基于lucene)的系统(同百度、google)。Hadoop因它而生。
Solr:Lucene下的子项目,基于Lucene构建的独立的企业级开源搜索平台,一个服务。它提供了基于xml/JSON/http的api供外界访问,还有web管理界面。
Elasticsearch:基于Lucene的企业级分布式搜索平台,它对外提供restful-web接口,让程序员可以轻松、方便使用搜索平台,而不需要了解Lucene。
 微信扫一扫
微信扫一扫