编辑导语:在支付产品中,你或许看到过这样一个产品——芝麻信用,它是衡量我们的信用程度的一大指标。那么,为什么要做这样一款产品以及它是如何评估我们的信用的。本文对芝麻信用进行了详细的介绍,一起来看看芝麻信用是怎么做的吧。


上周五在电脑里翻到一个文档,是芝麻信用的产品介绍。我不知道是从哪来的,也无法轻易搜到同一份文档。但既然是产品介绍,就权当这是公开文件,作为一个外行,聊聊。

我显然没做过芝麻信用分,甚至我都没有调研过,但我是做过同类产品的。这样一款信用产品,与那些消金信贷公司的A卡B卡是有很多不同的。这个行业里多了很多懂数据懂算法的人,但没几个懂信用懂风控的人。因而,我觉得这份不同,还是值得小书一下。
主要是揭秘下芝麻信用分是怎么做的,说是揭秘,但因为我并不是幕后操盘手,更准确的说法是推测,也可能只是臆断。
另外,花呗接入央行征信系统,我们这些消费者在使用这类产品时要不要另作考虑,也会说一说。
关于芝麻分,官网有一段介绍如下:
芝麻分是由独立第三方信用评估机构-芝麻信用管理有限公司,在用户授权的情况下,依据用户在互联网上的各类消费及行为数据,结合互联网金融借贷信息,运用云计算及机器学习等技术,通过逻辑回归、决策树、随机森林等模型算法,对各维度数据进行综合处理和评估,在用户信用历史、行为偏好、履约能力、身份特质、人脉关系五个维度客观呈现个人信用状况的综合分值。芝麻分的分值范围为350至950,分值越高代表信用越好,相应违约率相对较低,较高的芝麻分可以帮助用户获得更高效、更优质的服务。
01
信用衡量的就是先享后付的能力,那就是要让该享受服务的人能享受到服务。一个该一个能。该的人不能,不该的人能,是要解决的关键问题。
想清楚两件事情,你就知道怎么做这样一款产品了。
一是,哪些信息能衡量一个人的信用?
两个维度,一是能力,二是意愿。能力取决于你的收支情况,以及保持收支平衡的稳定性的水平。所以,你的就业、你的收入、你的消费很重要,不仅在于当前是什么水平,还在于它是不是稳定的。如果你四海为家,如果你黄赌毒,都是稳定性上的负面。
意愿的衡量本质在于违约的成本,这一定程度上和收支相关,但并不相同,因为数字化时代法律约束变弱了,更靠的是道德约束。这时候,意愿的刻画就很困难,但意愿体现在你的信用历史中。
一个月入十万的人找你借一万块钱,和一个每次借钱下个月都及时还钱的人找你借钱,你更愿意借给谁呢?
不管你去搜集哪些数据,它们都是刻画这两个指标的工具。
二是,做信用产品的根本目的是什么?
显然,做产品的目的是希望它能被用的尽可能多,但用的尽可能多一定是效果尽可能好吗?
答案是否定的。
企业做信用评分,讨好的是用户,但付费的是需要查询评分的商户。讨好的是用户是说,你要关注几乎所有用户的几乎所有方面的需求,不能仅仅是大部分用户的大部分需求,否则客诉可能让你的产品活不下去。企业要考虑面向用户可解释,商户不需要。
付费的是商户意味着,企业需要的是商户调用的越来越多,不是当前足够多,是长期足够多,而商户需要的是效果好,效果好就更精准,长期反而不会更多。两者的利益是不完全对等的。
这意味着,构建这样的模型时要根据经验挑选覆盖各个维度的变量,并使其保持绝对的可解释性,而不光是选择区分度高的变量。前者是芝麻信用这种产品的视角,后者是A/B/C/F卡的视角。
你说企业内部也要用啊,不需要效果尽可能好才更好吗?
企业又不是只用这一个工具。
02
我们来重点聊一聊芝麻信用的数据变量。
这个数据变量服务总共包含 65 个变量,按照芝麻信用评分维度(一级分类)和 DAS 变量类别(二级分类)分类如下:
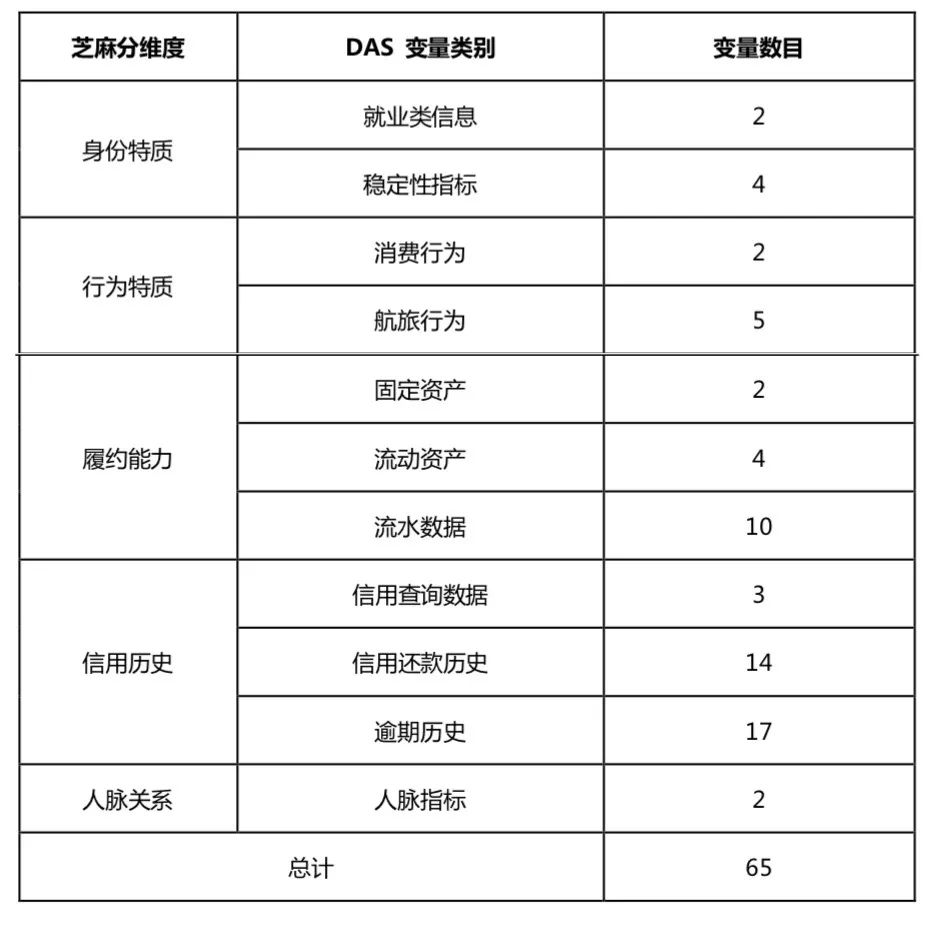
如前所述,相信你对这五大维度一点也不吃惊。身份特质、履约能力体现了“收”,行为特质体现了“支”,信用历史体现了意愿,人脉关系也体现了违约的成本项。
图中变量数量,基本就体现了这些类别的重要程度。信用历史往往是最重要的,其次是履约能力。
同样的一万块钱,借给一个每次借钱下个月都及时还钱的人,比借给一个月入十万的人靠谱的多。
这 65 个变量进一步拆分为 8 个核心变量和 57 个基础变量。
这些变量的分段逻辑,按文档的说法是,综合考虑 DAS 变量在全量芝麻用户上的数值分布对好坏用户的区分度将其进行分段,最多分十五段。分段序号 01-15 代表变量数值由小到大的排列顺序。
我们详细看一看这8个核心变量,57个基础变量汇总放在后面。

在身份特质项中,更核心的变量竟然是稳定性指标,而不是行职业信息。一方面是因为,行职业信息一般很难准确获取;另一方面,所在公司、所做职业是需要分类到大类上的,这类信息在住房按揭这种长期贷款中很重要,对短期借贷没有直接作用关系。不管是消费信贷,还是信用生活,还款能力的刻画完全不需要上升到行职业,反而稳定性指标更为重要。

第三方支付的核心在于深度和广度,支付业务要看广度,对应的当然要看用户使用第三方支付的广度。行为特质中,支付活跃场景数就很好的体现了这个广度。而支付金额和资产等维度在下面的履约能力中体现。
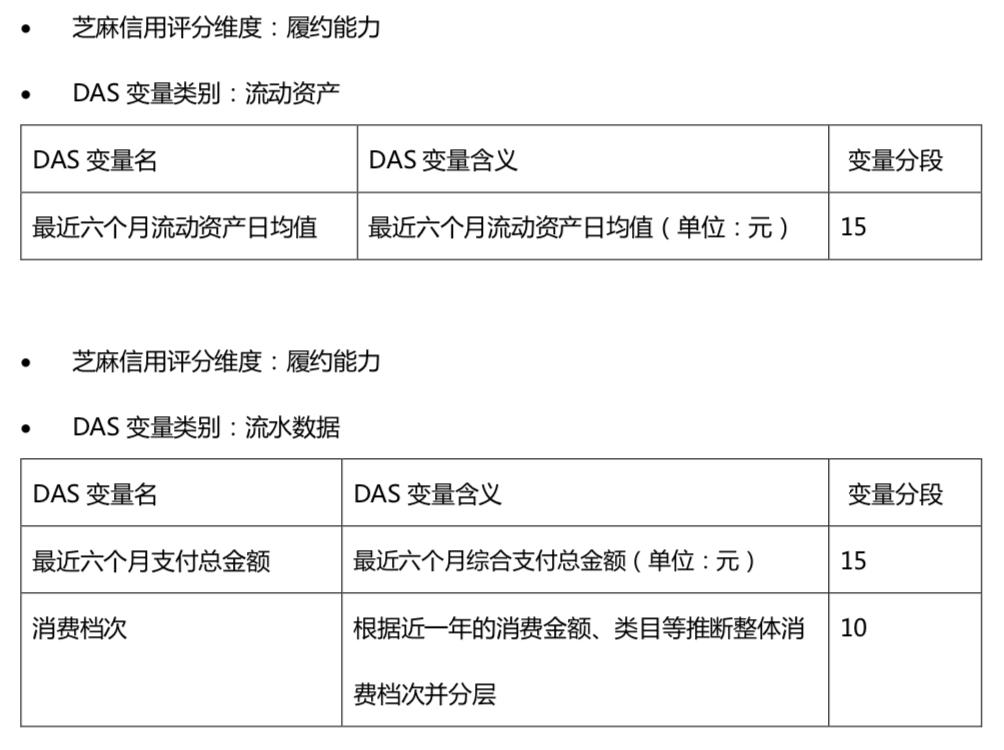
履约能力选取了一个资产一个支出一个消费层次。资产和支出不必说,消费层次意义在于,只消费生活必须品,和对精神物品有强烈需求的,代表了不同的层级。
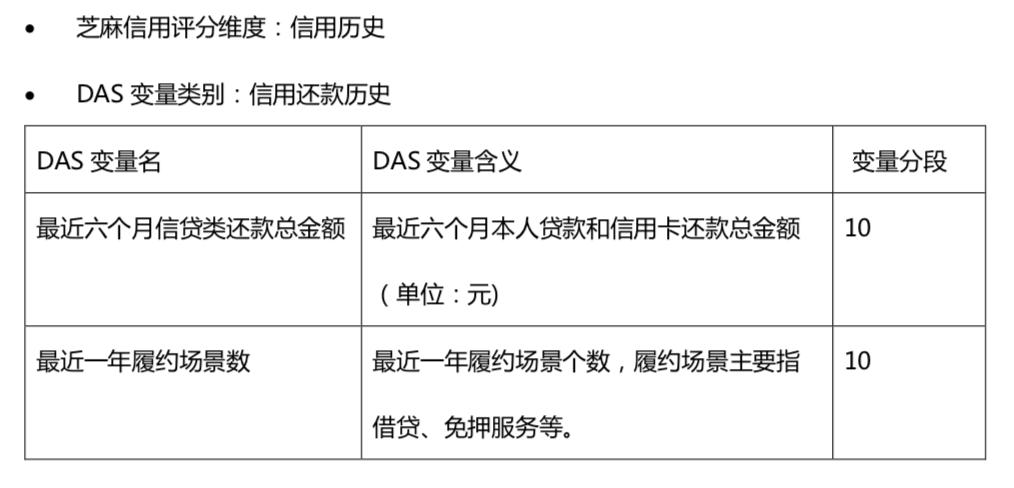
信用历史中更为关注信用还款,而非逾期,我推测原因有二,一是还款类的信息丰富度会高很多,二是正面信息在面向用户可见的产品上更为友好,它既能一定程度上起到和负面信息类似的效果,在相对关系上负面降分和正面增分区别不大,还能激励用户更高频高额地借还。
剩余 47 个基础变量,我整理如下。
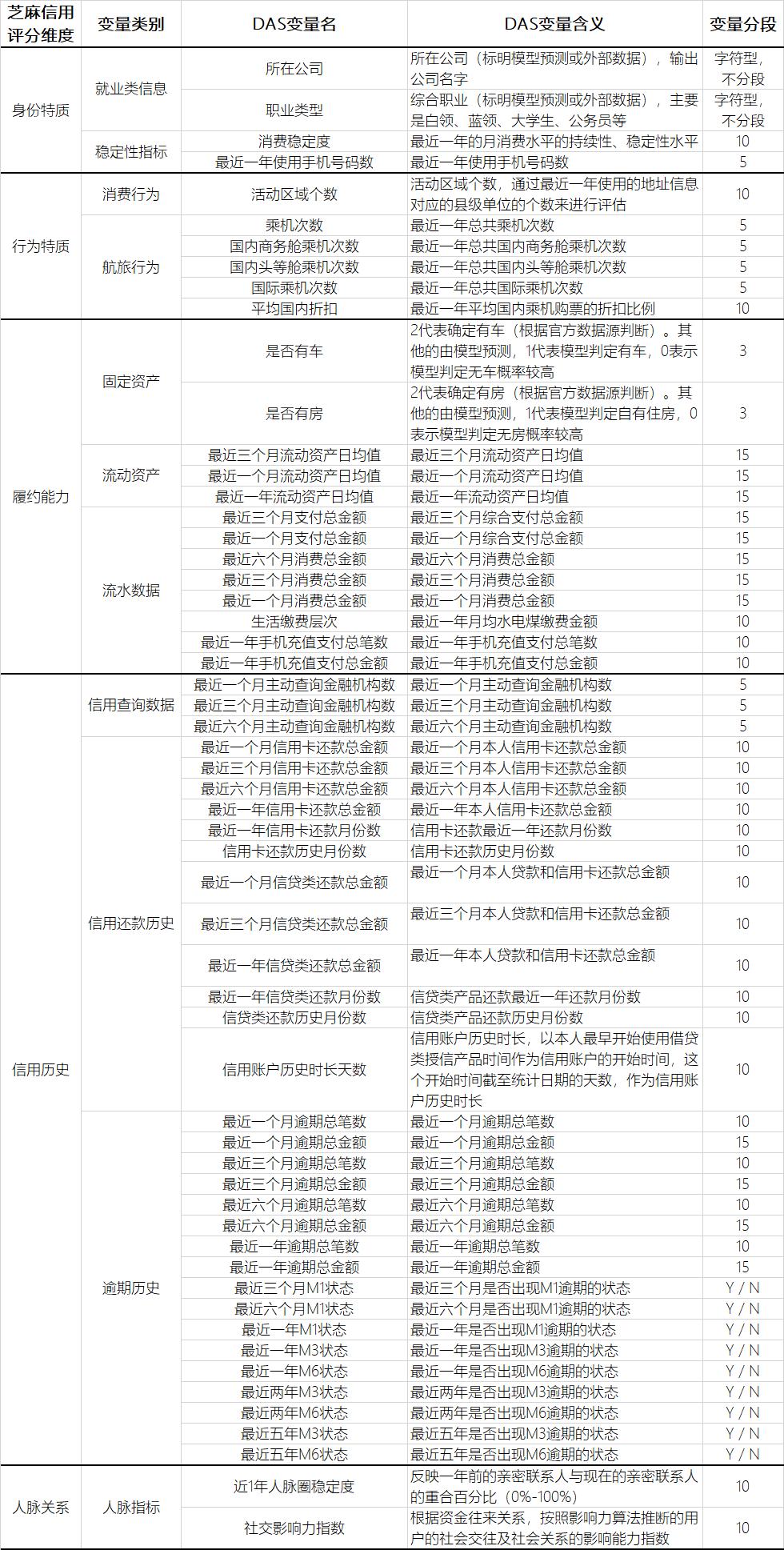
上述变量除了选取的指标值得学习外,时间窗口也很值得注意。另外,显而易见,这些变量很多都是相关的,它们都会被用在芝麻分里面吗?它们怎么综合得到一个芝麻信用分呢?
当然是通过权重进行组合。
权重如何得到?
“综合考虑 DAS 变量在全量芝麻用户上的数值分布对好坏用户的区分度将其进行分段”,既然变量的分组是参考了好坏用户的区分度的,专业名词就是WOE,那变量的组合当然是对好坏用户进行建模得到。
但是,这些变量,高度相关的变量,是会被评分卡筛选掉的。有效的模型不可能用到了其中所有的变量,即使有,我推测,很多变量也是人为地被赋予了无关痛痒的权重。
请注意,这是 DAS 变量数据服务文档,并未称作芝麻信用分产品介绍。我推测芝麻信用分的关键在那8个核心变量,我说的是关键,并不是说完全不用那57基础变量。
另外,芝麻分作为面向用户的产品,还兼有营销激励的功能,最终的芝麻分除模型计算外,应该还有其他环节的增减分设置。
03
花呗将全面接入央行征信系统,用户使用花呗需不需要担心哪些问题呢?
征信关乎个人信用,花呗是当代人超前消费的好助手,当它俩一拍即合,消费者应怎么考虑?
我不说责任和义务,也觉得有必要说几句。
现在大概央行收录的自然人11亿,其中有信贷数据的应该不到一半,我们消金业务发起申请查得率稍高一些,60%左右。也就是说,绝大多数人的征信数据信息是比较少的,就是那些简单的身份信息,没有金融信用数据。
传统的信用评估模型是根据一个人的借贷历史和还款表现,通过逻辑回归的方式来判断这个人的信用情况。现在越来越兴起大数据模型,它的数据源就十分广泛,包括电商、社交、搜索浏览等行为都产生了大量的数据。
所以,显然,花呗接入央行征信,对各大平台来说好处很大,因为用户的信用更好被评估了,那对用户来说呢,是不是就不好呢?
不是的,对用户来说其实影响不大,但要注意养成按时还款的习惯。
花呗对征信的补充,主要就影响了两点,借贷次数多了,逾期信息多了。
风控策略呢,也就是信用评估,借贷次数多了影响不大,次数再多也只算一个机构,一般不会认为这是坏行为,主要是逾期,逾期这种负面行为容易被风控拒绝,偶然性的逾期其实也不至于太坏。银行信审有个说法,称为“连3累6”,即连续出现三个月逾期,两年内共计六次逾期,这种属于严重的违约行为。但最好别逾期。
所以,可以照常用,养成按时还款的习惯基本就妥了。
我先是消费者,再是消金行业从业人员,我的立场始终是消费者。我说这话的一个依据是,对于《个人信息保护法》的出台,我第一感觉是这是好的,而不是这很糟糕。
04
还是要声明,上述说的很多事情,我并没有取证,甚至懒得找蚂蚁的朋友确认,我们有时候关注如何做一件事的原理和本质就够了,至于一个实例的所有detail,其实并没有太多价值去研究。就像,一个结构工程师盖房子,也实在没必要一定要知道建筑立面要做哪些装饰,这可能只是某些人的要求而已。
另外,我在
http://www.woshipm.com/data-analysis/5118872.html这篇文章中,提到过这几款信用评分,包括芝麻信用分、微信支付分和小白守约分。下面的说法来自那篇文章。
无论是天猫淘宝京东的消费还是花呗白条支付的海量交易数据,都可以用来评价个人的还款能力和意愿。结合着马斯洛需求理论,也就是生理、安全、情感、尊重、自我实现依次升级,越能体现高级需求的数据越可以给更高的权重。也就是说重要的不是单次购买行为,而是消费习惯。
而那些店铺商家,平台有他们所有的交易、资金、物流信息,都可以用来作为金融服务的依据。
你掌握了一个人的人际关系,就掌握了这个人。社交关系链,不仅可以用来评估信用,还能直接作为质押物,因为每个人都在乎它,而且很在乎。
我在知乎搜这个话题时,发现有不少问题在问如何提高芝麻分。也说一句。
如果你想要提升分数,就考虑下那些核心变量吧。另外值得注意的是,这些变量都是时间窗口的,并且是分段的,你的行为会被摊平到一段时间内,并且需要分段后跳档才能对结果产生影响。这给提升分数带来了难度,也是防止指标造假的科学手段。
本文由@雷帅 原创发布于人人都是产品经理。未经许可,禁止转载
 微信扫一扫
微信扫一扫